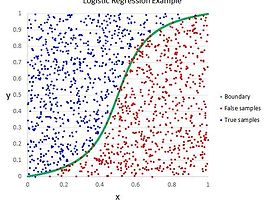
Paper Review 썸네일형 리스트형 BiDAF 리뷰 및 기록 Bi-Directional Attention Flow For Machine Comprehension We introduce the Bi-Directional Attention Flow (BiDAF) network, a hierarchical muti-stage architecture for modeling the representations of the context paragraph at different levels. BiDAF includes character-level, word-level, contextual embeddings, and query-aware context representation. MODEL Character Embedding Layer Maps each word to a h.. Fake News Detection on Social Media: A Data Mining Perspective Fake News Detection on Social Media: A Data Mining Perspective paper | dataset Fake News detection 문제를 2가지 관점으로 본다 Characterization Detection Contribution Discuss narrow ans broad definitions of fake news that cover most existing definitions in the literature and further present the unique characteristics of fake news on social media and its implications compared with the traditional media Give .. Enriching Word Vectors with Subword Information Enriching Word Vectors with Subword Information Word embedding 방법 중 FastText에 대한 리뷰입니다. paper | code Model Take into account morphology Consider subword units Represent words by a sum of its character n-grams skip-gram introduced by Mikolov et al. w∈{1,...,W}Maximize following log-likelihood∑t=1T∑c∈Ctlogp(wc∣wt)\begin{gathered} w\in\{1, ..., W\} \\ \text{Maximize following log-likelihood} \\ \d.. Joint Many-Task(JMT) Model 관련 paper 리뷰 A Joint Many-Task Model:Growing a Neural Network for Multiple NLP TasksKazuma Hashimoto, caiming Xiong, Yoshimasa Tsuruoka, and Richard SocherThe University of TokyoEMNLP 2017 Accepted 이번에 EMNLP 2017에 올라온 논문들을 살펴보다가, Growing Neural Network와 Multiple NLP Tasks라는 키워드에 이끌려 읽게 되었다. 살펴보면 5개의 Task(POS tagging, Chunking, Dependency Parsing, Relatedness, Textual Entailment)에서 굉장히 간단한 Network Model을 이용해 .. 간단한 Softmax Regression Softmax Regression Softmax Regression(multinomial logistic regression)은 “0” 또는 “1”만 다루는 것이 아닌 multiple classes를 다루기 위해 logistic regression을 일반화한 기법이다. 손글시 분류인 MNIST example에선 0~9라는 10 class를 사용했다. Input으로 가 주어졋을 때, hypothesis 는 각 에 대한 확률 를 계산해야한다. 이렇게 계산하고 나면 hypothesis의 결과 값은 -dimensional vector(다 더하면 1이되는)다 된다. 음.. 이 외에 딱히 적어야 할 말은 없을 것 같다. 정말로 logistic 에서 0, 1과 같은 binary class가 아닌 multi class.. 간단한 Logistic Regression Logistic Regression Logistic Regression은 확률 모델 중 하나로써, 독립변수의 선형 결합을 이용해 사건의 발생 가능성을 예측하는데 사용되는 통계 기법이다. Linear Regression 분석 방법과 유사하나 Linear Regression의 경우 연속된 값을 예측할 때 쓰이고, Logistic Regression의 경우 0 혹은 1로 표현되는 discrete한 값을 예측할 때 쓰인다. 일반적으로 이러한 문제는 Classification이라 할 수 있다. Linear Regression에서 의 번째 값을 예측한다고 할 때, 함수를 이용하게된다. 하지만 이런 함수는 binary-valued labels()과 같은 값을 예측하는 문제에서는 유용하지 않다. 그래서 Logistic.. Linear Regression Linear Regression 선형성1이라는 기본 가정이 충족된 상태에서 독립변수와 종속변수의 관계를 설명하거나 예측하는 통계 방법. 여기서 내가 간단하게 내린 결론은, 어떠한 vector가 주어지고, 그 에 대한 결과 vector가 주어졌을 때, 그 둘의 관계를 linear function으로 설명하고, 를 모르는 또 다른 가 주어졌을 때, 값을 예측한다는 것이다. 독립변수 , 상수항 와 종속변수() 사이의 관계를 모델화 하는 것 아래와 같이 표현될 수 있다. 아래 그림과 같이 빨간 점들을 데이터라고 하면, 각 데이터의 관계에 대해 표현하면 아래와 같은 선이 나온다. 이 때, 수식 (1)에서 , 이 된다. 그러면 (1)의 수식에서 와 는 어떻게 구할것인가? 변수 와 의 관계를 가장 잘 나타낸다는 의미.. 간단한 Vector Space Model 설명 Vector Space Model Vector Space Model 또는 Term Vector Model은 문서 혹은 단어를 Vector 형태로 나타내는 것이며 텍스트 문서를 단어 색인등의 식별자로 구성된 벡터로 표현하는 대수적 모델이다. 정보검색, 정보 필터링 및 검색 엔진의 색인이나 연관도 순위에 사용된다. 이러한 Vector Space Model에서 어떠한 문서 는 -dimensional vector로 표현된다. 이러한 dimension은 서로 구분되는 Term 으로 되어있고, 은 모든 문서 집합에서 사용되는 Term의 개수이다. 문서 가 term 를 포함하지 않으면 는 0이다. 문서를 Vector Space Model에 문서를 표현하는 여러가지 방법이 있는데 그 중에 Boolean Model을 이.. 이전 1 2 다음