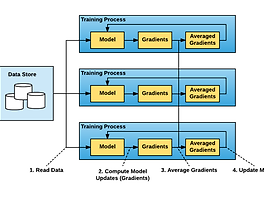
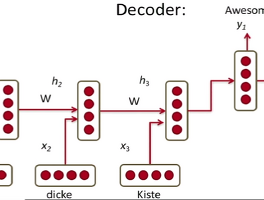
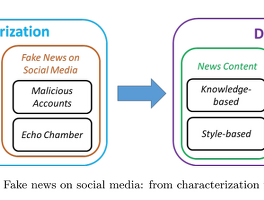
pytorch 1.0, distributed training 관련 기록 pytorch 1.0이 release 됐고, 관련 내용들을 적어놓은 blog post에 대한 기록https://code.fb.com/ai-research/pytorch-developer-ecosystem-expands-1-0-stable-release/ pytorch 관련 projectsHorovod - a distributed training framework that makes it easy for developers to take a single-GPU program and quickly train it on multiple GPUsPytorch Geometry - a geometric computer vision library for PyTorch that provides a set of rout.. BiDAF 리뷰 및 기록 Bi-Directional Attention Flow For Machine Comprehension We introduce the Bi-Directional Attention Flow (BiDAF) network, a hierarchical muti-stage architecture for modeling the representations of the context paragraph at different levels. BiDAF includes character-level, word-level, contextual embeddings, and query-aware context representation. MODEL Character Embedding Layer Maps each word to a h.. zsh, oh-my-zsh에서 home/end 키가 안될 때 그냥 개인 기록용... 환경:Ubuntu 16.04Xshell 을 이용한 ssh 연결zsh shell과 oh-my-zsh 를 설치후 사용 중 문제:vi/vim 내에선 home/end 키가 정상적으로 작동shell 에서 home/end 키가 원하는대로 작동하지 않음home 키 입력 시 아무일도 일어나지 않음end 키 입력 시 ~ 문자 삽입이 일어남 해결:vi ~/.zshrc아래 두줄 추가bindkey "\033[1~" beginning-of-linebindkey "\033[4~" end-of-line [cs224n] Lecture 9 Machine Translation and Advanced Recurrent LSTMs and GRUs Machine Translation and Advanced Recurrent LSTMs and GRUs [slide] [video] Gated Recurrent Units by Cho et al. (2014) Long-Short-Term-Memories by Hochreiter and Schmidhuber (1997) Recap Word2Vec Jt(θ)=logσ(uoTvc)+∑j−P(w)[logσ(−ujTvc)]J_t(\theta)=\log{\sigma(u_o^Tv_c) + \sum_{j - P(w)}[\log{\sigma(-u_j^Tv_c)}]}Jt(θ)=logσ(uoTvc)+j−P(w)∑[logσ(−ujTvc)] GloVe J(θ)=12∑i,j=1Wf(Pij)(uiTvj−logPij.. Fake News Detection on Social Media: A Data Mining Perspective Fake News Detection on Social Media: A Data Mining Perspective paper | dataset Fake News detection 문제를 2가지 관점으로 본다 Characterization Detection Contribution Discuss narrow ans broad definitions of fake news that cover most existing definitions in the literature and further present the unique characteristics of fake news on social media and its implications compared with the traditional media Give .. [cs224n] Lecture 4 Word Window Classification and Neural Networks Word Window Classification and Neural Networks Overview Classification background Updating word vectors for classificaiton Window classification & cross entropy derivation tips A single layer neural network Max-Margin loss ans backprop 지금까지 Skip-gram & CBOW 등을 이용한 Word2Vec 방법은 Unsupervised Method 였다. Goal: p(y∣x)=exp(Wyx)∑c=1Cexp(Wcx) p(y|x)=\frac{exp(W_yx)}{\sum_{c=1}^Cexp(W_cx)} p(y∣x)=∑c=1Ce.. Enriching Word Vectors with Subword Information Enriching Word Vectors with Subword Information Word embedding 방법 중 FastText에 대한 리뷰입니다. paper | code Model Take into account morphology Consider subword units Represent words by a sum of its character n-grams skip-gram introduced by Mikolov et al. w∈{1,...,W}Maximize following log-likelihood∑t=1T∑c∈Ctlogp(wc∣wt)\begin{gathered} w\in\{1, ..., W\} \\ \text{Maximize following log-likelihood} \\ \d.. [cs224n] Lecture 1 Natural Language Processing with Deep Learning Natural Language Processing with Deep Learning 최근에 NLP 관련해서 stanford의 cs224n 강의를 듣게 됐다. 강의 하나씩 들으면서 간단하게 정리도 하면서 나중에 다시 볼 겸 블로그에 남기려고 한다. Plan What is Natural Language Processing? The nature of human language What is Deep Learning Why is language understanding difficult Intro to the application of Deep Learning of NLP What is Natural Language Processing? NLP Applications Spell checking, keyword .. 이전 1 2 3 4 ··· 7 다음